问题描述
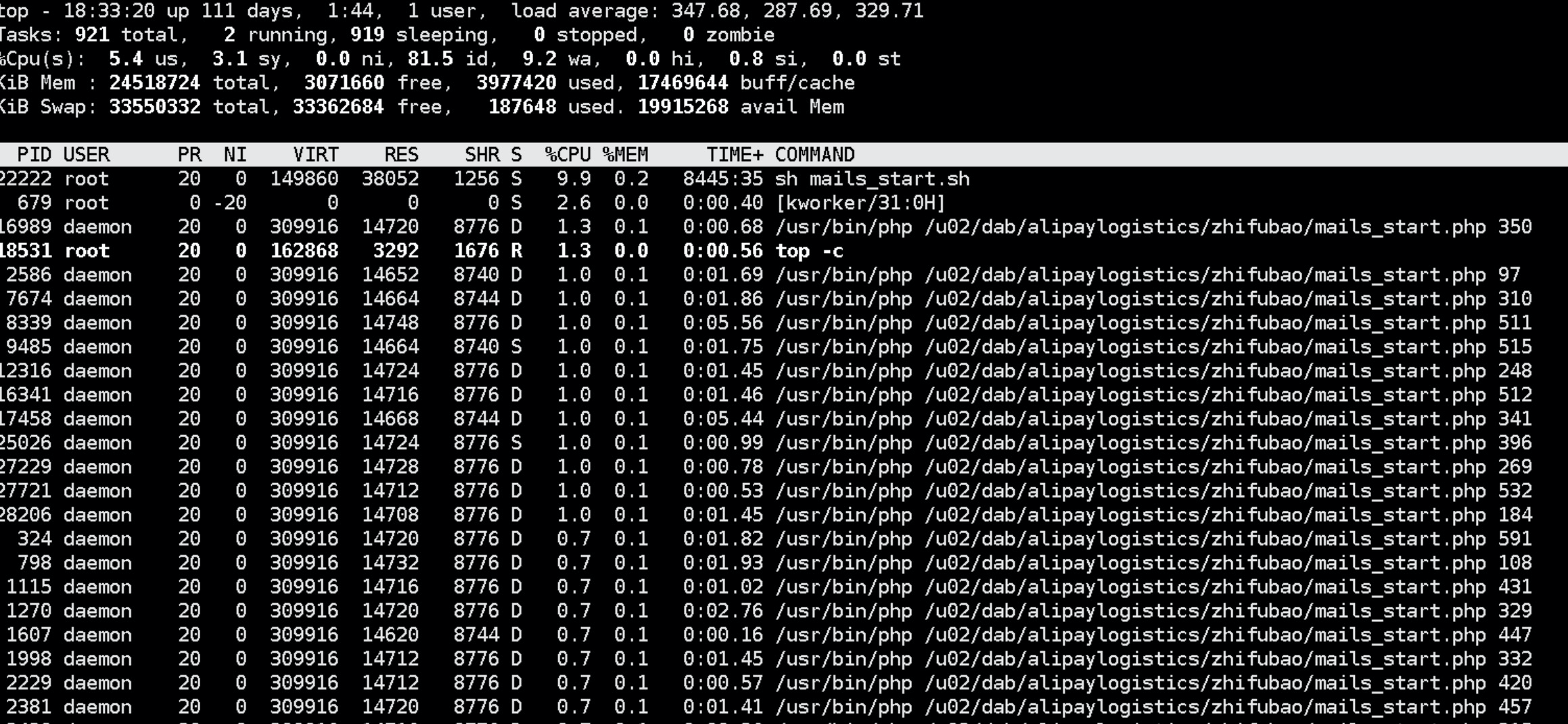
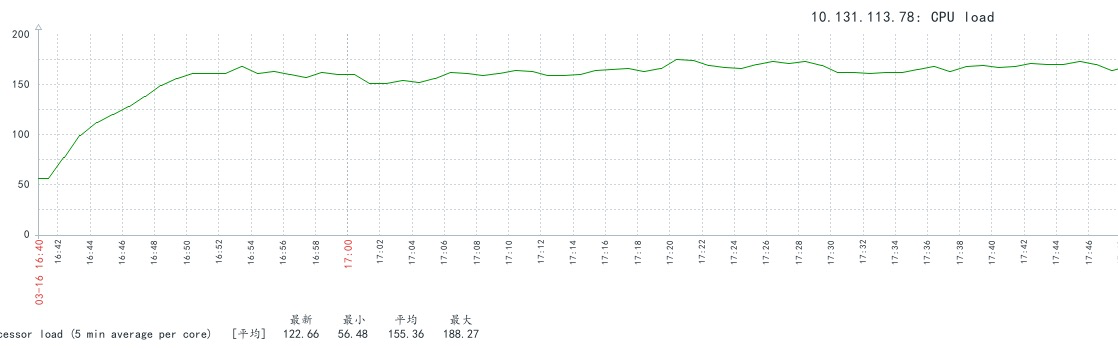
昨天下午优化了物流推送的代码,快下班的时候收到了告警短信,显示消费队列堆积。遂登录zabbix观察服务器资源情况,发现cpu飙升。
问题处理
刚开始以为是代码原因。是否由于来源非tb,进程(循环消费3000条)在秒级的时间单位类销毁创建。600个消费者是否在不停的创建销毁,cpu肯定会飙升。观察当天日志目录,未生成因来源问题的日志。故可以排除此项。尝试屏蔽了几处直接过滤的判断,让一个进程走更长的时间,这样进程就不会不停的销毁创建了。但是多次尝试,发现还是这样?。无奈,为了脚本能正常运行,不至于消费过慢,联系运维版本回退。
再次查找
再次开始查找原因,发现cpu飙升是从16:30左右开始的。查找聊天记录,优化升级14:40就已经完成了。就算消费一条消息要0.5秒,3000条也应该在30分钟内完成。如果代码有问题,15:10分之前就应该出现问题。而不是运行这么久,更加坚信了问题不再消费者脚本。在聊天记录中发现,16:30进行了一个操作,把日志统一放到了nas中。难道是因为写日志文件引起的问题。原来有两台消费服务器,日志各自放在服务器本地。将日志统一放到nas后,两台服务器900个消费进程同时写一个文件。问题可能在文件锁
查看写日志代码
file_put_contents($logFile, $content,FILE_APPEND); #FILE_APPEND 追加写入
此处未加锁,但是FILE_APPEND保证文件内容不会覆盖,所有日志都追加了只是会有顺序错乱的可能性。
而LOCK_EX就是解决这个问题的(FILE_APPENF|LOCK_EX)。
问题有可能出在FILE_APPEND,模拟测试代码如下
test.php
for ($i=0;$i<30000;$i++) {
file_put_contents('test.log',$i."\n",FILE_APPEND);
}
test.sh
#!/bin/bash
exec_path=pwd
while true
do
for i in {1..100}
do
exec_command="ps -ef | grep '$exec_path/test.php $i\$' | grep -v grep | wc -l"
count=$(eval $exec_command)
current_cpu=0
let "current_cpu=i % 8"
if [ $count -lt "1" ];then
php $exec_path/test.php $i > /dev/null &
fi
done
# sleep 1
done

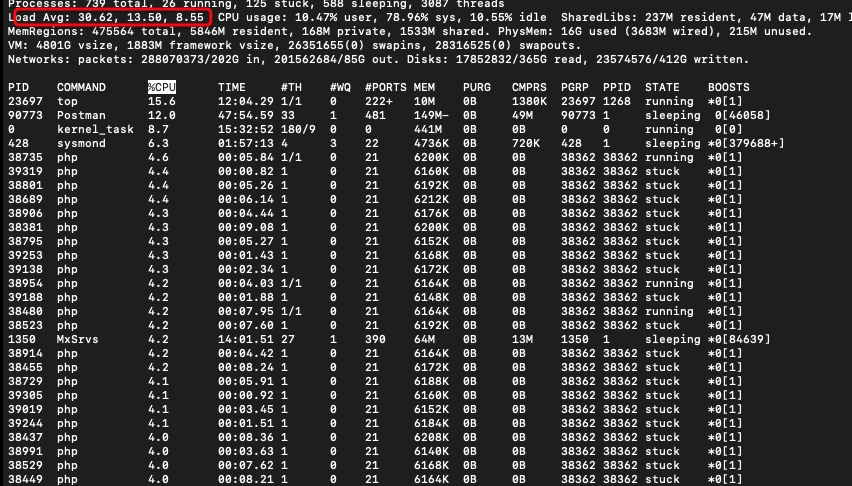
极耗cpu,故由此推断是由此引起。
top 查看cpu说明
- load average 0.00 0.00 0.00 分别是1分钟 5分钟 15分钟的负载情况
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。- Task 现有921个进程,运行中2,休眠919,stoped状态0,zombie状态(僵尸)0
- Cpu(s) cpu状态
5.4 us — 用户空间占用CPU的百分比。
3.1 sy — 内核空间占用CPU的百分比。
0.0 ni — 改变过优先级的进程占用CPU的百分比
81.5 id — 空闲CPU百分比
9.2 wa — IO等待占用CPU的百分比
0.0 hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.8 si — 软中断(Software Interrupts)占用CPU的百分比- KiB Mem 内存状态
24518724 total — 物理内存总量(23.4GB)
3071660 free — 空闲内存总量(2.9GB)
3977420 used — 使用中的内存总量(3.7GB)
17469644 buff/cache — 缓存的内存量 (16.7GB)- KiB Swap swap交换分区
33550332 total — 交换区总量(32G)
33362684 free — 空闲交换区总量(31.8G)
187648 used — 使用的交换区总量(183M)
19915268 cached — 缓冲的交换区总量(19G)- 输入命令大写P以cpu排序,输入命令大写M以内存排序
- mac 输入命令o 再输入排序字段