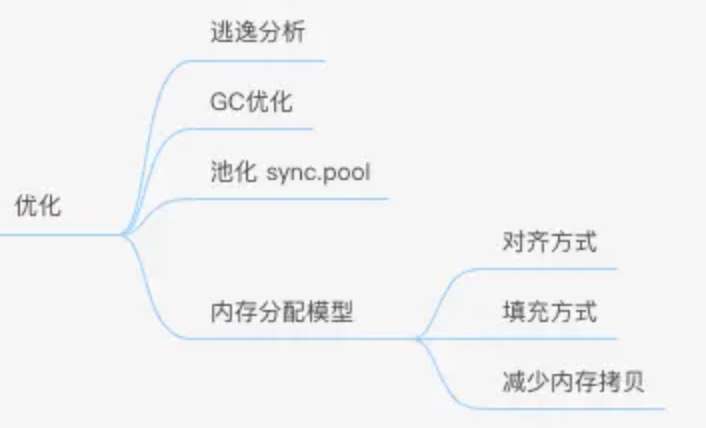
逃逸分析
在 C 语言中,可以使用 malloc 和 free 手动在堆上分配和回收内存。Go 语言中,堆内存是通过垃圾回收机制自动管理的,无需开发者指定。那么,Go 编译器怎么知道某个变量需要分配在栈上,还是堆上呢?编译器决定内存分配位置的方式,就称之为逃逸分析(escape analysis)。逃逸分析由编译器完成,作用于编译阶段。
go run -gcflags "-m -l" main.go
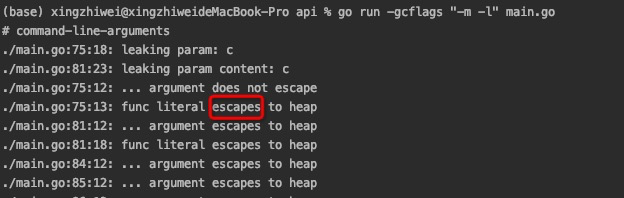
- 指针逃逸
指针逃逸应该是最容易理解的一种情况了,即在函数中创建了一个对象,返回了这个对象的指针。这种情况下,函数虽然退出了,但是因为指针的存在,对象的内存不能随着函数结束而回收,因此只能分配在堆上。
interface{}动态类型逃逸
在 Go 语言中,空接口即
interface{}可以表示任意的类型,如果函数参数为interface{},编译期间很难确定其参数的具体类型,也会发生逃逸。栈空间不足
操作系统对内核线程使用的栈空间是有大小限制的,64 位系统上通常是 8 MB。可以使用
ulimit -a命令查看机器上栈允许占用的内存的大小。对于 Go 语言来说,运行时(runtime) 尝试在 goroutine 需要的时候动态地分配栈空间,goroutine 的初始栈大小为 2 KB。当 goroutine 被调度时,会绑定内核线程执行,栈空间大小也不会超过操作系统的限制。
对 Go 编译器而言,超过一定大小的局部变量将逃逸到堆上,不同的 Go 版本的大小限制可能不一样。
闭包
func Increase() func() int {
n := 0
return func() int {
n++
return n
}
}
func main() {
in := Increase()
fmt.Println(in()) // 1
fmt.Println(in()) // 2
}
Increase() 返回值是一个闭包函数,该闭包函数访问了外部变量 n,那变量 n 将会一直存在,直到 in 被销毁。很显然,变量 n 占用的内存不能随着函数 Increase() 的退出而回收,因此将会逃逸到堆上。
GC优化
传值vs传指针
传值会拷贝整个对象,而传指针只会拷贝指针地址,指向的对象是同一个。传指针可以减少值的拷贝,但是会导致内存分配逃逸到堆中,增加垃圾回收(GC)的负担。在对象频繁创建和删除的场景下,传递指针导致的 GC 开销可能会严重影响性能。
一般情况下,对于需要修改原对象值,或占用内存比较大的结构体,选择传指针。对于只读的占用内存较小的结构体,直接传值能够获得更好的性能。
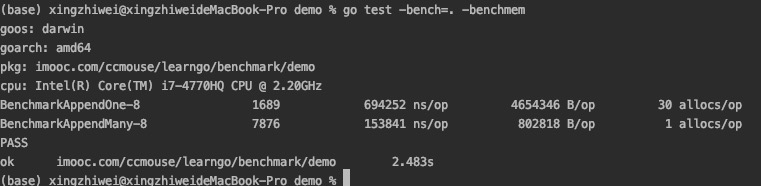
slice 预先分配内存
当slice的容量小于1024时,容量是按照2倍大小增长的。当容量大于1024,增长的容量是原来的1.25倍
/**
* slice.go
*/
package demo
func appendOne(num int) []int {
var res []int
for i := 0; i < num; i++ {
res = append(res, i)
}
return res
}
func appendMany(num int) []int {
res := make([]int, 0, num)
for i := 0; i < num; i++ {
res = append(res, i)
}
return res
}
/**
* slice_test.go
*/
package demo
import "testing"
func BenchmarkAppendOne(b *testing.B) {
num := 100000
for i := 0; i < b.N; i++ {
_ = appendOne(num)
}
}
func BenchmarkAppendMany(b *testing.B) {
num := 100000
for i := 0; i < b.N; i++ {
_ = appendMany(num)
}
}
go test -bench=. -benchmem
map中保存值,而不是指针
使用分段map
可以看到,使用分段的,保存值的map的GC耗时最小
使用struct{}优化
struct{}经过编译器特殊优化,指向同一个内存地址(runtime.zerobase),不占用空间。
GC分析工具
go tool pprfo
go tool trace
go run -gcflags "-m -l" main.go
GODEBUG="gctrace=1"
池化 sync.pool
保存和复用临时对象,减少内存分配,降低 GC 压力
json 的反序列化在文本解析和网络通信过程中非常常见,当程序并发度非常高的情况下,短时间内需要创建大量的临时对象。而这些对象是都是分配在堆上的,会给 GC 造成很大压力,严重影响程序的性能。
Go 语言从 1.3 版本开始提供了对象重用的机制,即 sync.Pool。sync.Pool 是可伸缩的,同时也是并发安全的,其大小仅受限于内存的大小。sync.Pool 用于存储那些被分配了但是没有被使用,而未来可能会使用的值。这样就可以不用再次经过内存分配,可直接复用已有对象,减轻 GC 的压力,从而提升系统的性能。
sync.Pool 的大小是可伸缩的,高负载时会动态扩容,存放在池中的对象如果不活跃了会被自动清理。
使用
package main
import (
"encoding/json"
"fmt"
"sync"
)
type Student struct {
Name string
Age int32
Remark [1024]byte
}
var studentPool = sync.Pool{New: func() interface{} {
return new(Student)
}}
func main() {
var buf, _ = json.Marshal(Student{Name: "Geektutu", Age: 25})
stu := studentPool.Get().(*Student)
json.Unmarshal(buf, stu)
studentPool.Put(stu)
fmt.Println(stu)
}
内存分配模型