指针
go语言没有指针运算
& 取地址符
*指针可以指向任何类型 以下面代码为例,指针指向int类型
var pi *int
var i int = 8
pi = &i
指针的作用,传递参数
GMP模型
Go Runtime将Goroutines(G)安排到逻辑处理器(P)执行。每个P都有一台机器(M)
Go从1.5版本之后将默认的P的数量改为 = CPU core的数量(实际上还乘以了每个core上硬线程数量)
内存管理
入门
软件在操作系统上运行时,需要访问计算机RAM(随机读取内存)以:
- 加载需要执行的自己的字节码
- 存储被执行的程序使用的数据值和数据结构
- 加载程序执行所需的任何运行时系统
当软件使用内存是,除了用于加载字节码的空间外,它们使用的两个内存区域,即堆栈(栈)和堆内存(堆)。
栈
用于静态内存分配,顾名思义,它是后进后出(LIFO)堆栈(将其视为一栈框)
- 由于这种性质,从堆栈中存储和检索数据的过程非常快,因为不需要查找,您只需从堆栈的最顶层块存储和检索数据。
- 但这意味着存储在堆栈上的任何数据必须是有限和静态的(数据的大小在编译时已知)。
- 这里是函数的执行数据以栈帧的形式存储(所以,这就是实际的执行栈 ) 。每个帧都是存储该函数所需数据的一块空间。例如,每次函数声明新变量时,它都会被“推送”到堆栈中最顶层的块上。然后,每次函数退出时,最上面的块都会被清除,因此该函数推送到堆栈上的所有变量都被清除。由于存储在这里的数据的静态性质,这些可以在编译时确定。
- 多线程应用每个线程可以有一个堆栈。
- 堆栈的内存管理简单明了,由操作系统完成。
- 存储在堆栈上的典型数据是局部变量(值类型或原语、原语常量)、指针和函数帧。
- 在这里,您将遇到堆栈溢出错误,因为与堆相比,堆栈的大小有限。
- 对于大多数语言来说,可以存储在堆栈上的值大小都有限制。
堆
堆是用来进行动态内存分配的,与栈不同,程序需要使用指针查找堆中的数据(把它想象成一个大型多级库 ) 。
- 它比堆栈慢,因为查找数据的过程更复杂,但它可以存储比堆栈更多的数据。
- 这意味着动态大小的数据可以存储在这里。
- 堆在应用程序的线程之间共享。
- 由于其动态性质,堆管理起来更棘手,这是大多数内存管理问题的产生地,也是语言自动内存管理解决方案发挥作用的地方。
- 存储在堆上的典型数据是全局变量、引用类型(如对象、字符串、映射和其他复杂的数据结构)。
- 如果您的应用程序试图使用比分配的堆更多的内存,您将遇到内存错误(尽管这里还有许多其他因素在起作用,如GC,压缩)。
- 一般来说,可以存储在堆上的值的大小没有限制。当然,分配给应用程序的内存上限是存在的。
与硬盘驱动器不同,RAM不是无限的。如果一个程序在不释放内存的情况下继续消耗内存,最终它会耗尽内存并崩溃,甚至更糟地崩溃操作系统。因此,软件程序不能随心所欲地使用RAM,因为这会导致其他程序和进程耗尽内存。因此,大多数编程语言没有让软件开发人员解决这个问题,而是提供了自动内存管理的方法。当我们谈论内存管理时,我们主要谈论的是管理堆内存。
内存分为栈存储区和堆存储区,每个Goroutine(G)有一个栈。在这里存储了静态数据,包括函数栈帧,静态结构,原生类型值和指向动态结构的指针。这与分配给每个P的mcache不是一回事。
内存管理包括在需要内存时自动分配,不需要内存时进行垃圾回收。这是有标准库完成的(runtime包)
内存分配
每个Go程序进程都被操作系统(OS)分配了一些虚拟内存,这是进程可以访问的总内存。在虚拟内存中使用的实际内存称为常驻集。这个空间由内部内存结构管理如下:
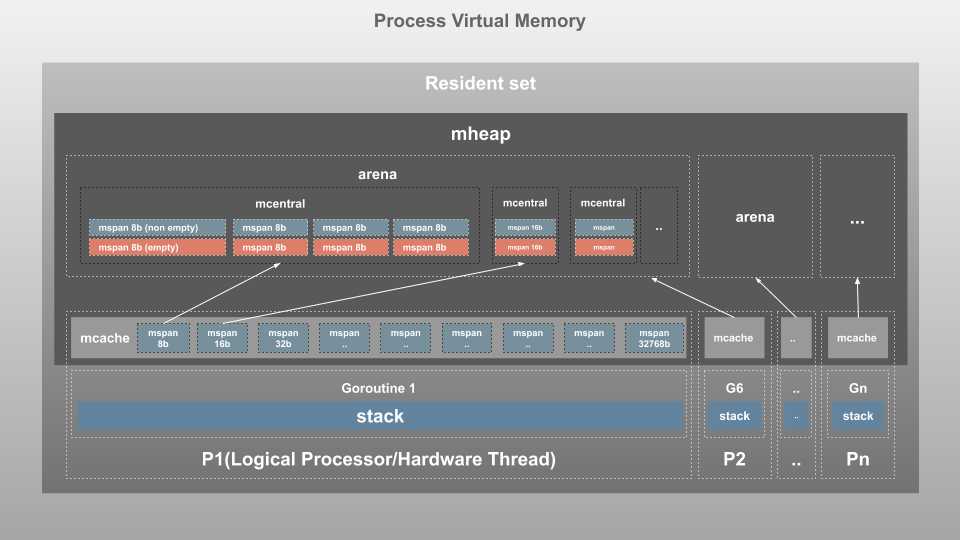
这是一个基于Go使用的内部对象的简化视图,实际上,Go将内存分割和分组为页面
正如你所看到的,这里没有代际记忆。造成这种情况的主要原因是TCMalloc(线程缓存Maloc),这是Go自己的内存分配器所模仿的。
Page Heap(mheap)
这就是Go存储动态数据的地方(任何大小的数据在编译时无法计算)。这是最大的内存块,也是垃圾收集(GC)发生的地方。
常驻集分为每个8KB的页面,由一个全局mheap对象管理。
大对象(大小>32kb的对象)直接从
mheap*分配。这些大请求是以牺牲中央锁为代价的,因此在任何给定的时间点只能满足**一个*P*的请求。*
- mspan:
mspan是管理mheap内存页的最基本结构。这是一个双链表,包含起始页面的地址、跨度大小类和跨度中的页面数量。与TCMalloc一样,Go还将内存页面按大小分为67个不同类,从8字节到32千字节不等,如下图所示

每个跨度存在两次,一个用于有指针的对象(扫描类),一个用于没有指针的对象(noscan类)。这在GC期间有帮助,因为noscan跨度不需要遍历来查找活动对象。
- mcentral:
mcentral将相同大小类别的跨度组合在一起。每个mcentral包含两个mspanList: - 空:span 的双链表,没有空闲对象或缓存在
mcache. 当这里的一个跨度被释放时,它被移动到非空列表中。 非空:具有自由对象的跨度双链表。当从 请求新的跨度时
mcentral,它会从非空列表中获取它并将其移动到空列表中。当
mcentral没有任何空闲跨度时,它会从mheap获取arena:堆内存中分配的虚拟内存中根据需要增长和收缩。当需要更多内存时,
mheap将它们从虚拟内存中提取为 64MB(对于 64 位体系结构)的块,称为arena. 这些页面在这里映射到跨度。- mcache:这是一个非常有趣的构造。
mcache是提供给P(逻辑处理器)的内存缓存,用于存储小对象(对象大小 <= 32Kb)。虽然这类似于线程堆栈,但它是堆的一部分,用于动态数据。mcache包含scan和所有类大小的noscan类型mspan。Goroutines 可以在mcache没有任何锁的情况下获取内存,因为一次P只能有一个G在运行。因此,这更有效。mcache从mcentral需要时请求新的跨度。
<16B
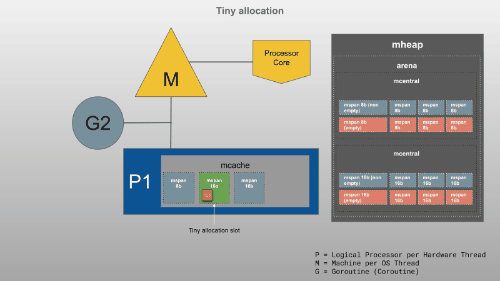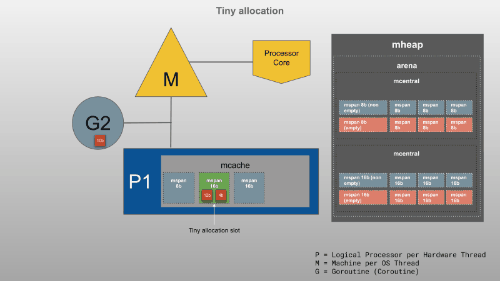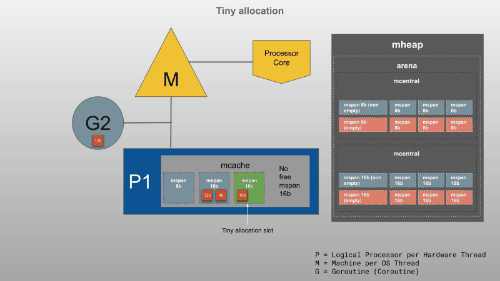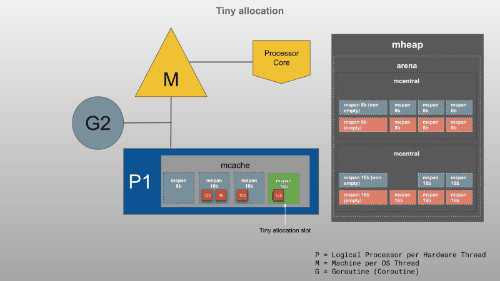
16B~32KB
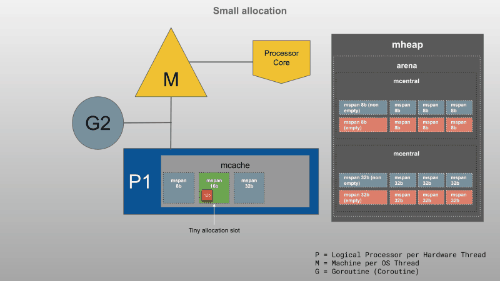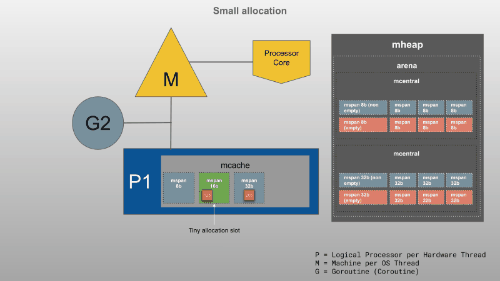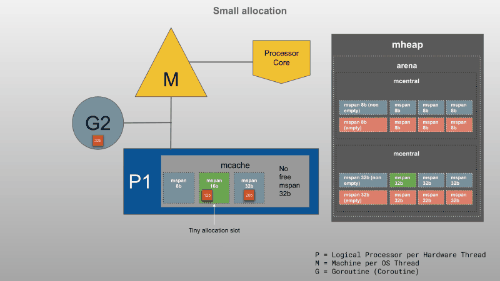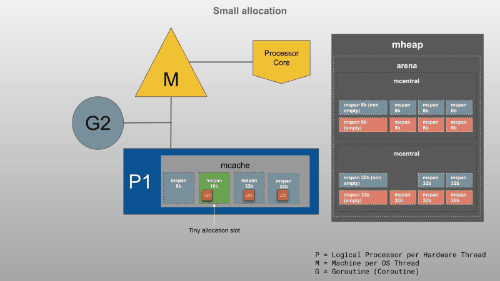
>32KB

小知识 tcmalloc分配算法 (Thread Cache Malloc)
GC
gc清理的是堆内
- 我们正在查看单个 Goroutine,实际过程为所有活动的 Goroutine 执行此操作。首先打开写屏障。
- 标记过程选择一个 GC 根并将其着色为黑色,并以深度优先的树状方式从中遍历指针,它将遇到的每个对象标记为灰色
- 当它在一个
noscan范围内到达一个对象或者当一个对象没有更多的指针时,它会结束根并拿起下一个 GC 根对象 - 一旦扫描了所有 GC 根,它就会选择一个灰色对象并继续以类似的方式遍历其指针
- 如果在写屏障打开时有任何指向对象的指针更改,该对象将变为灰色,以便 GC 重新扫描它
- 当没有更多灰色对象时,标记过程完成并关闭写屏障
- 分配开始时将进行清扫
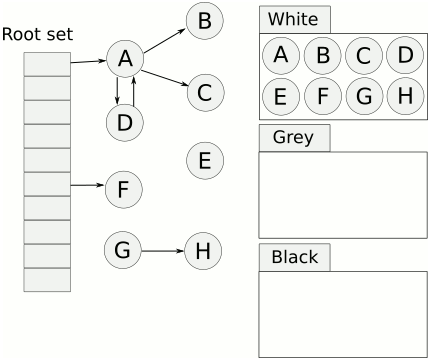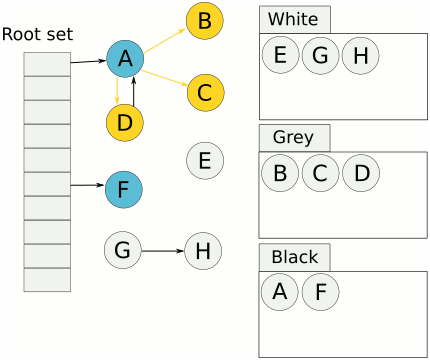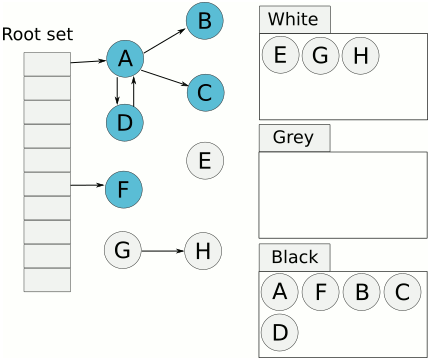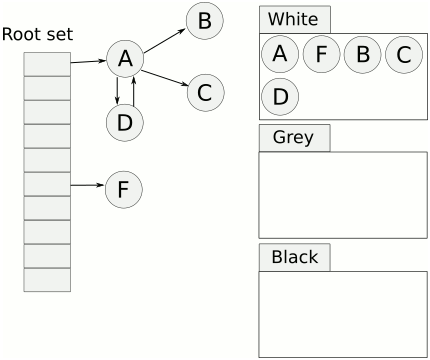
根对象
在垃圾回收的术语中,由叫做根集合。他是垃圾回收器在标记过程中最先检查的对象,包括:
- 全局变量:程序在编译期就能确定的哪些存在于程序整个生命周期的变量
- 执行栈:每个goroutine都包含自己的执行栈,这些执行栈上的变量及指向分配的堆内存块的指针
- 寄存器:寄存器的值可能表示一个指针,参与计算的这些指针可能指向某些赋值器分配的堆内存区块
三色标记法
Golang的GC算法主要是基于标记-清扫(mark and sweep)算法,并在此基础上做了改进。
性能提升,减少了STW时间(stop the world)
非分代的、非移动的、并发的、三色的标记清除垃圾收集器
go gc流程
| 阶段 | 说明 | 赋值器状态 |
|---|---|---|
| GCMark | 标记准备阶段,为并发标记做准备工作,启动写屏障 | STW |
| GCMark | 扫描标记阶段,与赋值器并发执行,写屏障开启 | 并发 |
| GCMark Termination | 标记终止阶段,保证一个周期内标记任务完成,停止写屏障 | STW |
| GCoff | 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭 | 并发 |
| GCoff | 内存归还阶段,将过多的内存归还给操作系统,写屏障关闭 | 并发 |
混合写屏障(hybrid write barrier)
由于标记操作和用户逻辑是并发执行的,用户逻辑会时常生成对象或者改变对象的引用。例如把⼀个对象标记为白色准备回收时,用户逻辑突然引用了它,或者又创建了新的对象。由于对象初始时都看为白色,会被 GC 回收掉,为了解决这个问题,引入了写屏障机制。
GC 对扫描过后的对象使⽤操作系统写屏障功能来监控这段内存。如果这段内存发⽣引⽤改变,写屏障会给垃圾回收器发送⼀个信号,垃圾回收器捕获到信号后就知道这个对象发⽣改变,然后重新扫描这个对象,看看它的引⽤或者被引⽤是否改变。利⽤状态的重置实现当对象状态发⽣改变的时候,依然可以再次其引用的对象。
go gc总结
无分代、不整理、并发的三色标记法
- 对象整理目的:是解决内存碎片问题,但是Go给予tcmalloc分配算法,基本没有碎片问题。
另外顺序内存分配器在多线程并不适用,整理内存对tcmalloc分配没有实质提升 - 分代GC目标主要是针对新创建对象,不会频繁检查所有对象。但是Go会通过逃逸分析将大部分“新生”对象存储在栈上,需要长期保存的对象存在于堆中。栈会被回收,不需要GC。
Go的GC更专注于如何让GC和用户代码并发执行,专注于减少STW时间