解决NameNode 单点问题
一变多
Active挂掉Standby立刻接管
两个NN的与数据的同步
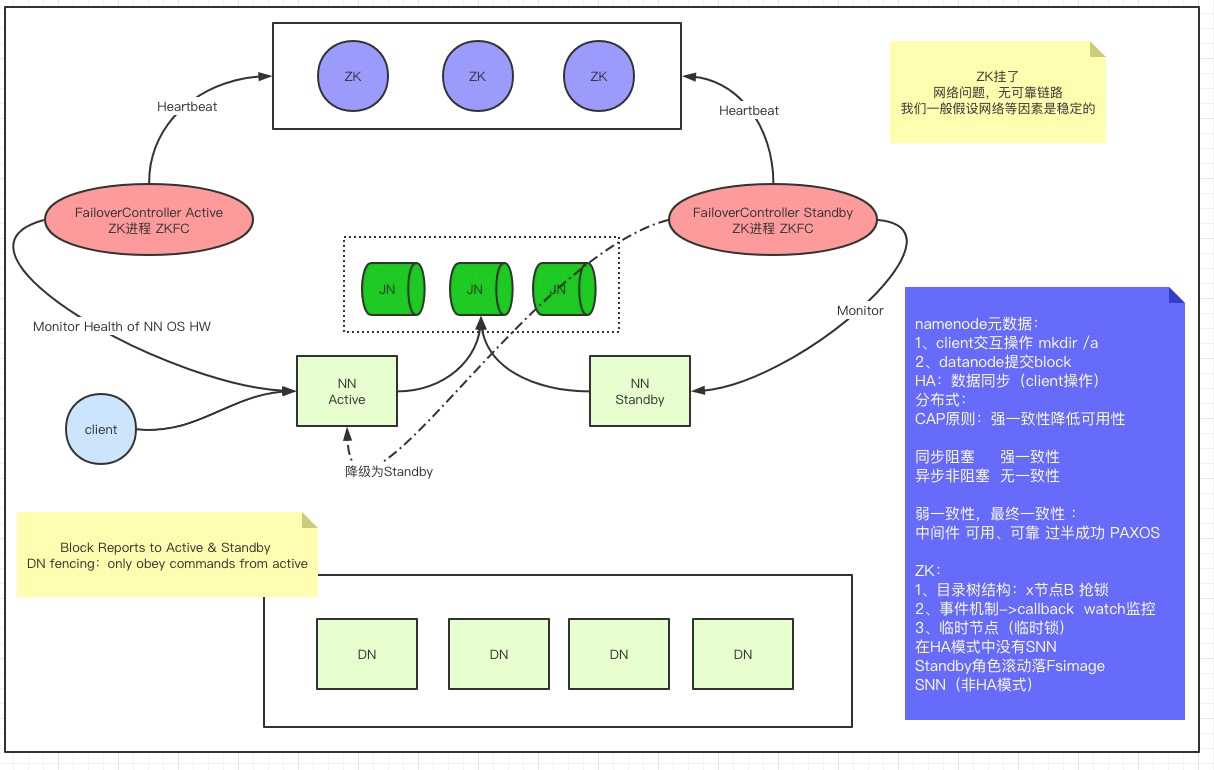
ZKFC 三只手
1、判定本机进程状态
2、zk目录下同一个节点
3、降级(设置原Active为Standby),升级(本机为Active)
Active挂掉
- ZKFC删除锁
产生事件,触发回调,抢锁
确定原Active降级或异常
升级本机
ZKFC挂掉
- 临时节点删除,即删除锁
同上2,3,4
Active 网络问题,但和客户端通,和Standby不通
- 临时节点删除,即删除锁
产生事件,触发回调,抢锁
Standby 的 ZKFC无法连接Active,无法确定状态
本机不升级 (宁可不可用,也不能脑裂)
| HOST | NN | NN | JNN | DN | ZKFC | ZK |
|---|---|---|---|---|---|---|
| node01 | * | * | * | |||
| node02 | * | * | * | * | * | |
| node03 | * | * | * | |||
| node04 | * | * |
完全分布式到HA搭建
HA模式下:有一个问题,NN是2台。某一个时刻,谁是Active呢?客户端只能连接Active
core-site.xml
fs.defaultFs -> hdfs://node01:9000
配置:
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--ZK-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
<!--journal node-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bigdata/hadoop/ha/dfs/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- zkfc 自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
分发配置
scp core-site.xml hdfs-site.xml node02:`pwd`
流程
- 基础设施
ssh免密:
1)启动start-dfs.sh脚本的机器,需要将共钥分发给别的节点
2)在HA模式下,每一个NN会启动ZKFC。ZKFC会用免密的方式控制自己和其他NN节点的NN状态 应用搭建
HA依赖zk 搭建ZK集群
修改hadoop的配置文件,并集群同步初始化启动
1)先启动JN:hadoop-daemon.sh start journalnode
2)选择一个NN做格式化:hdfs namenode -format <只有第一次搭建做,以后不用做>
3)启动这个格式化的NN,以备另外一台同步 hadoop-daemon.sh start namenode
4)在另外一台机器中:hdfs namenode -bootstrapStandby
5)格式化zk:hdfs zkfc -formatZK <只有第一次搭建做,以后不用做>
6)start-dfs.sh使用验证
1)去看jn的日志和目录变化:
2)node04 zkCli.sh 启动之后可以看到锁 /hadoop-ha/mycluster/ActiveStandbyElectorLock
3)杀死namenode 杀死zkfc kill -9 xxx
a)杀死active NN
b)杀死active NN的zkfc
c)shutdown active NN主机的网卡: ifconfig eth0 down
2节点一直阻塞降级
如果恢复1上的网卡 ifconfig eht0 up
最终 2变成active
很详细,实用
膜拜大神,双击666