架构
| Hiv Cli | MetaStore Server | MySQL | |
|---|---|---|---|
| node01 | * | ||
| node02 | * | ||
| node03 | *(远程数据库模式) | ||
| node04 | * |

配置
Server Configuration Parameters
| Config Param | Config Value | Commen |
|---|---|---|
| javax.jdo.option.ConnectionURL | jdbc:mysql://host name/database name?createDatabaseIfNotExist=true | metadata is stored in a MySQL server |
| javax.jdo.option.ConnectionDriverName | com.mysql.jdbc.Driver | MySQL JDBC driver class |
| javax.jdo.option.ConnectionUserName | user name | user name for connecting to MySQL server |
| javax.jdo.option.ConnectionPassword | password | password for connecting to MySQL server |
| hive.metastore.warehouse.dir | base hdfs path | default location for Hive tables. |
| hive.metastore.thrift.bind.host | host_name | Host name to bind the metastore service to. When empty, “localhost” is used. This configuration is available Hive 4.0.0 onwards. |
Client Configuration Parameters
| Config Param | Config Value | Comment |
|---|---|---|
| hive.metastore.uris | thrift://host_name:port | host and port for the Thrift metastore server. If hive.metastore.thrift.bind.host is specified, host should be same as that configuration. Read more about this in dynamic service discovery configuration parameters. |
| hive.metastore.local | false | Metastore is remote. Note: This is no longer needed as of Hive 0.10. Setting hive.metastore.uri is sufficient. |
| hive.metastore.warehouse.dir | base hdfs path | Points to default location of non-external Hive tables in HDFS. |
hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node02:9083</value>
</property>
</configuration>
初始化数据库
node02
schematool -dbType mysql -initSchema
启动
元数据服务
node02
hive --service metastore
CLI
node01
hive
Hive SQL
人员表
id,姓名,爱好,住址
1,小明1,lol-book-movie,benjing:chaoyao-shanghai:pudong
2,小明2,lol-book-movie,benjing:chaoyao-shanghai:pudong
3,小明3,lol-book-movie,benjing:chaoyao-shanghai:pudong
4,小明4,lol-book-movie,benjing:chaoyao-shanghai:pudong
5,小明5,lol-movie,benjing:chaoyao-shanghai:pudong
建表语句
create table psn2
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
插入数据
# 不加 local 会去 hdfs 找数据文件
load data local inpath '/root/data/data' into table psn2;
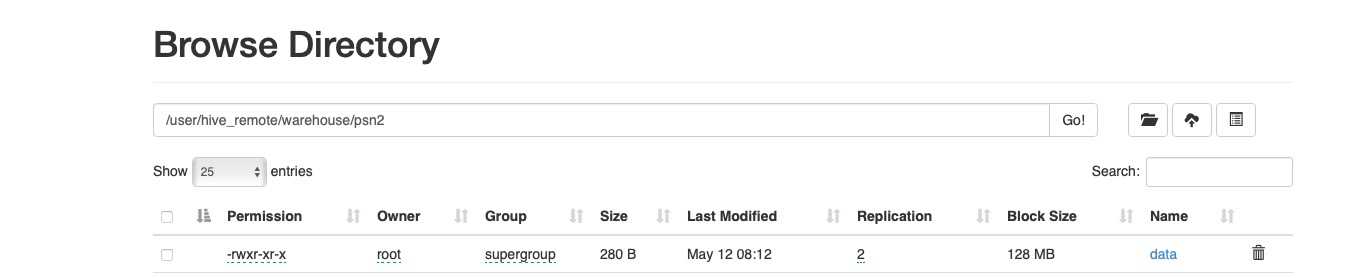
直接上传到hdfs目录
data2
81,小明81,lol-book-movie,benjing:chaoyao-shanghai:pudong
82,小明82,lol-movie,benjing:chaoyao-shanghai:pudong
hdfs dfs -put ./data2 /user/hive_remote/warehouse/psn2
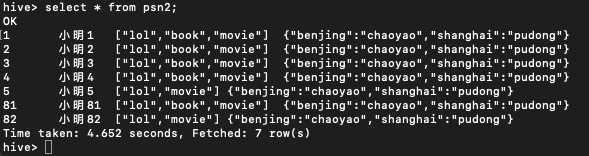
内部表和外部表

hvie在默认情况下创建的是内部表
如何创建外部表?
create external table psn4 (
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/hive_data';
内部表和外部表的区别
#加载数据
load data local inpath '/root/hive/data' into tables psn4;
#查看
select * from psn4;

数据位置
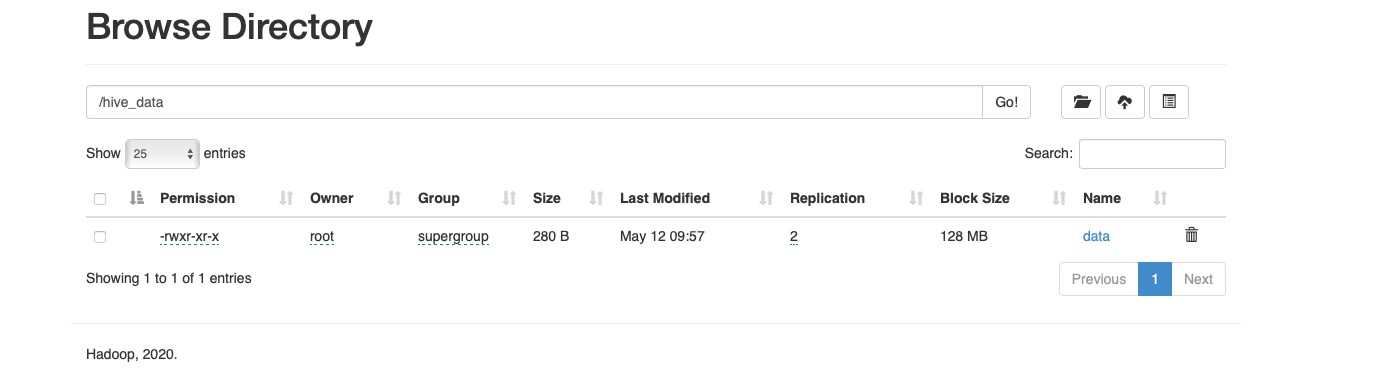
1、hive内部表创建的时候数据存储在hive的默认存储目录中,外部表在创建的时候需要指定额外的目录
2、hive内部表删除的时候,会将元数据和数据都删除,而外部表只会删除元数据,不会删除数据
应用场景:
内部表:需要先创建表,然后向表中添加数据,适合做中间表的存储
外部表:可以先创建表,再添加数据,也可以先有数据,再创建表,本质上是将hdfs的某一个目录的数据跟 hive的表关联映射起来,因此适合原始数据的存储,不会因为误操作将数据给删除掉
hive的分区表:
hive默认将表的数据保存在某一个hdfs的存储目录下,当需要检索符合条件的某一部分数据的时候,需要全量 遍历数据,io量比较大,效率比较低,因此可以采用分而治之的思想,将符合某些条件的数据放置在某一个目录 ,此时检索的时候只需要搜索指定目录即可,不需要全量遍历数据。
建表语句
create table psn5 (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' ;
插入数据
load data local inpath '/root/hive/data' into table psn5 partition(gender='man');

hdfs目录结构
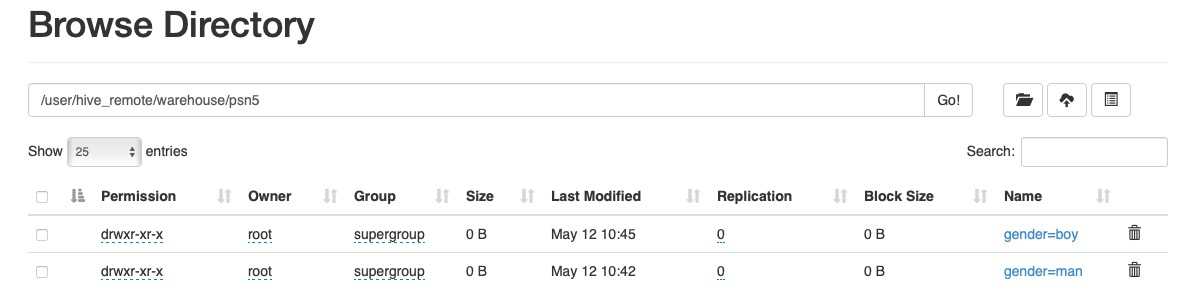
创建多分区表
create table psn6 (
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string,age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' ;

1、当创建完分区表之后,在保存数据的时候,会在hdfs目录中看到分区列会成为一个目录,以多级目录的形式 存在
2、当创建多分区表之后,插入数据的时候不可以只添加一个分区列,需要将所有的分区列都添加值
3、多分区表在添加分区列的值得时候,与顺序无关,与分区表的分区列的名称相关,按照名称就行匹配
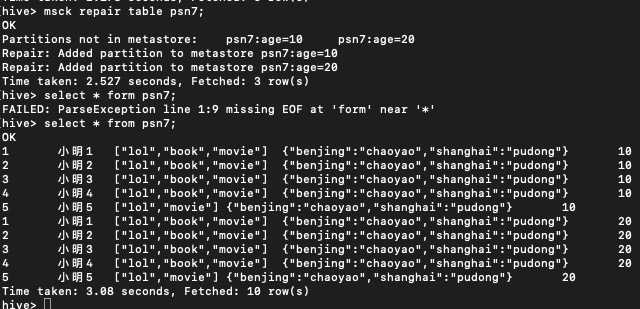
修复分区
create external table psn7
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/msb';
msck repair table psn7;
在使用hive外部表的时候,可以先将数据上传到hdfs的某一个目录中,然后再创建外部表建立映射关系,如果在上传数据的时候,参考分区表的形式也创建了多级目录,那么此时创建完表之后,是查询不到数据的,原因是分区的元数据没有保存在mysql中,因此需要修复分区,将元数据同步更新到mysql中,此时才可以查询到元数据。具体操作如下: