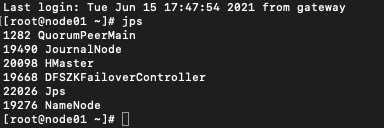
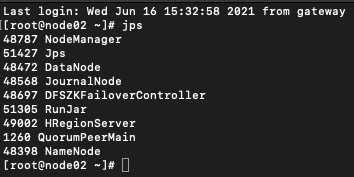
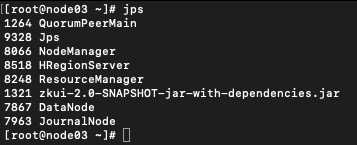
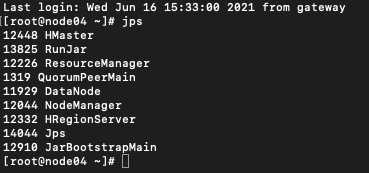
环境准备
数据预处理
hive建表
应用词表:
CREATE EXTERNAL TABLE IF NOT EXISTS dim_rcm_hitop_id_list_ds
(
hitop_id STRING,
name STRING,
author STRING,
sversion STRING,
ischarge SMALLINT,
designer STRING,
font STRING,
icon_count INT,
stars DOUBLE,
price INT,
file_size INT,
comment_num INT,
screen STRING,
dlnum INT
)row format delimited fields terminated by '\t';
用户历史下载表:
CREATE EXTERNAL TABLE IF NOT EXISTS dw_rcm_hitop_userapps_dm
(
device_id STRING,
devid_applist STRING,
device_name STRING,
pay_ability STRING
)row format delimited fields terminated by '\t';
正负例样本表:
CREATE EXTERNAL TABLE IF NOT EXISTS dw_rcm_hitop_sample2learn_dm
(
label STRING,
device_id STRING,
hitop_id STRING,
screen STRING,
en_name STRING,
ch_name STRING,
author STRING,
sversion STRING,
mnc STRING,
event_local_time STRING,
interface STRING,
designer STRING,
is_safe INT,
icon_count INT,
update_time STRING,
stars DOUBLE,
comment_num INT,
font STRING,
price INT,
file_size INT,
ischarge SMALLINT,
dlnum INT
)row format delimited fields terminated by '\t';
load数据
分别往三张表load数据:
商品词表:
load data local inpath '/root/recommender/data/applist.txt' into table dim_rcm_hitop_id_list_ds;
用户历史下载表:
load data local inpath '/root/recommender/data/userdownload.txt' into table dw_rcm_hitop_userapps_dm;
正负例样本表:
load data local inpath '/root/recommender/data/sample.txt' into table dw_rcm_hitop_sample2learn_dm;
构建测试数据集
创建临时表
处理数据时所需要的临时表
CREATE TABLE IF NOT EXISTS tmp_dw_rcm_hitop_prepare2train_dm
(
device_id STRING,
label STRING,
hitop_id STRING,
screen STRING,
ch_name STRING,
author STRING,
sversion STRING,
mnc STRING,
interface STRING,
designer STRING,
is_safe INT,
icon_count INT,
update_date STRING,
stars DOUBLE,
comment_num INT,
font STRING,
price INT,
file_size INT,
ischarge SMALLINT,
dlnum INT,
idlist STRING,
device_name STRING,
pay_ability STRING
)row format delimited fields terminated by '\t';
最终保存训练集的表
CREATE TABLE IF NOT EXISTS dw_rcm_hitop_prepare2train_dm
(
label STRING,
features STRING
)row format delimited fields terminated by '\t';
训练数据预处理过程
首先将数据从正负例样本和用户历史下载表数据加载到临时表中
INSERT OVERWRITE TABLE tmp_dw_rcm_hitop_prepare2train_dm
SELECT
t2.device_id,
t2.label,
t2.hitop_id,
t2.screen,
t2.ch_name,
t2.author,
t2.sversion,
t2.mnc,
t2.interface,
t2.designer,
t2.is_safe,
t2.icon_count,
to_date(t2.update_time),
t2.stars,
t2.comment_num,
t2.font,
t2.price,
t2.file_size,
t2.ischarge,
t2.dlnum,
t1.devid_applist,
t1.device_name,
t1.pay_ability
FROM
(
SELECT
device_id,
devid_applist,
device_name,
pay_ability
FROM
dw_rcm_hitop_userapps_dm
) t1
RIGHT OUTER JOIN
(
SELECT
device_id,
label,
hitop_id,
screen,
ch_name,
author,
sversion,
IF (mnc IN ('00','01','02','03','04','05','06','07'), mnc,'x') AS mnc,
interface,
designer,
is_safe,
IF (icon_count <= 5,icon_count,6) AS icon_count,
update_time,
stars,
IF ( comment_num IS NULL,0,
IF ( comment_num <= 10,comment_num,11)) AS comment_num,
font,
price,
IF (file_size <= 2*1024*1024,2,
IF (file_size <= 4*1024*1024,4,
IF (file_size <= 6*1024*1024,6,
IF (file_size <= 8*1024*1024,8,
IF (file_size <= 10*1024*1024,10,
IF (file_size <= 12*1024*1024,12,
IF (file_size <= 14*1024*1024,14,
IF (file_size <= 16*1024*1024,16,
IF (file_size <= 18*1024*1024,18,
IF (file_size <= 20*1024*1024,20,21)))))))))) AS file_size,
ischarge,
IF (dlnum IS NULL,0,
IF (dlnum <= 50,50,
IF (dlnum <= 100,100,
IF (dlnum <= 500,500,
IF (dlnum <= 1000,1000,
IF (dlnum <= 5000,5000,
IF (dlnum <= 10000,10000,
IF (dlnum <= 20000,20000,20001)))))))) AS dlnum
FROM
dw_rcm_hitop_sample2learn_dm
) t2
ON (t1.device_id = t2.device_id);

然后再利用python脚本处理格式
这里要先讲python脚本加载到hive中
ADD FILE /root/recommender/script/dw_rcm_hitop_prepare2train_dm.py;
可以通过list files;查看是不是python文件加载到了hive
目的:将当前浏览的appID与用户历史下载表中的appid形成关联特征
在hive语句中调用python脚本
在hive中使用python脚本处理数据的原理:
Hive会以输出流的形式将数据交给python脚本,python脚本以输入流的形式来接受数据,接受来数据以后,在python中进行一系列的数据处理,处理完毕后,又以输出流的形式交给Hive,交给了hive就说明了就处理后的数据成功保存到hive表中了
INSERT OVERWRITE TABLE dw_rcm_hitop_prepare2train_dm
SELECT
TRANSFORM (t.*)
USING 'python dw_rcm_hitop_prepare2train_dm.py'
AS (label,features)
FROM
(
SELECT
label,
hitop_id,
screen,
ch_name,
author,
sversion,
mnc,
interface,
designer,
icon_count,
update_date,
stars,
comment_num,
font,
price,
file_size,
ischarge,
dlnum,
idlist,
device_name,
pay_ability
FROM
tmp_dw_rcm_hitop_prepare2train_dm
) t;
导出训练数据
将处理完成后的训练数据导出用做线下训练的源数据
注:这里是将数据导出到本地,方便后面再本地模式跑数据,导出模型数据。这里是方便演示真正的生产环境是直接用脚本提交spark任务,从hdfs取数据结果仍然在hdfs,再用ETL工具将训练的模型结果文件输出到web项目的文件目录下,用来做新的模型,web项目设置了定时更新模型文件,每天按时读取新模型文件